Journal of Alzheimers Disease & Parkinsonism
������
Our Group organises 3000+ Global Events every year across USA, Europe & Asia with support from 1000 more scientific Societies and Publishes 700+ ������ Journals which contains over 50000 eminent personalities, reputed scientists as editorial board members.
������ Journals gaining more Readers and Citations
700 Journals and 15,000,000 Readers Each Journal is getting 25,000+ Readers
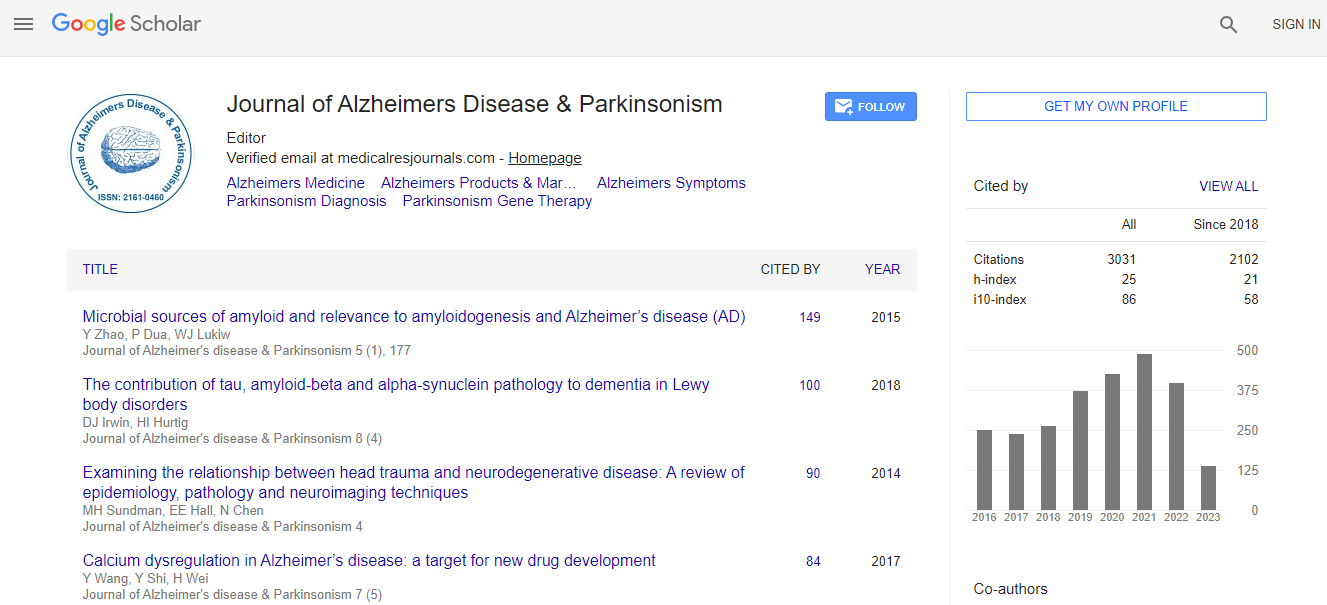
Citations : 4334
Indexed In
- Index Copernicus
- Google Scholar
- Sherpa Romeo
- Open J Gate
- Genamics JournalSeek
- Academic Keys
- JournalTOCs
- China National Knowledge Infrastructure (CNKI)
- Electronic Journals Library
- RefSeek
- Hamdard University
- EBSCO A-Z
- OCLC- WorldCat
- SWB online catalog
- Virtual Library of Biology (vifabio)
- Publons
- Geneva Foundation for Medical Education and Research
- Euro Pub
- ICMJE
Useful Links
Recommended Journals
Related Subjects
Share This Page
Classification of demented and non-demented patients using longitudinal statistics
11th International Conference on Vascular Dementia
Shyamal Chakraborty
Kothari Medical Centre, India
ScientificTracks Abstracts: J Alzheimers Dis Parkinsonism
DOI:
Abstract
In this work, we propose a framework to do classification between demented and nondemented patients using longitudinal statistical analysis. Though in practice, we often use the detailed clinical findings to establish a possible hypothesis about, whether the patient has dementia or not, nonetheless an automatic algorithm to identify a patient to be demented (D)/ non-demented (ND) is required. Some of the recent works in this regime includes [1,2,3]. We propose an algorithm for this automatic identification based on a sequence of MR scans collected over a time period. The proposed algorithm is based on the research of the second author have done during his PhD at University of Florida, USA. Before going into the detail of our experimental setup, we will briefly describe the proposed algorithm. Given a temporal sequence of MR scans for a patient (identified with a path on a high dimensional hypersphere), we identified the temporal sequence as the “average” of the data points on the path and the variation, captured by the principal subspace. This identification is robust to any affine transformation of the path including rotation, translation of the MR scans. Notice that in the collection time of MR scans, the scans can be a transformation of each other due to several aspects including alignment of a patient, MRI machine etc. In order to test our proposed framework, we used the benchmark OASIS dataset, which consists of at least two MR brain scans of each of the 150 subjects, aged between 60 to 90 years. In order to avoid gender effects, we have used MR scans of male patients from three visits separated by at least one year. In our dataset, we have 12 ND and 11 D subjects. We have computed an atlas from the MR scans and non-rigidly register each scan to the atlas to identify each MR scan as a point on the unit hyperpshere of dimension 892. For each subject, this essentially gives us a path on the hypersphere. After using our representation mentioned in the previous paragraph, for each subject we have identification with a point on the hypersphere and a subspace (capturing the variation in the path). We used a standard nearest average classifier. We first computed the average path for each class (D and ND) over the training data. Then for a test subject we assign it to the class with the nearest average path. Due to the small amount of data, we have chosen a leave-one-out framework, i.e., we randomly put aside one subject from each class and then use the rest of the subjects for training and repeat this process. Using this classification framework, we can correctly identify 11 out of 12 ND subjects and 10 out of 11 D subjects, achieving 91.3% classification accuracy. The above experimentation is a clear indication of the usefulness of an automatic differentiation technique between demented and non-demented subjects. As a future direction, we want to investigate our proposed framework on large scale data t sets..Biography
Dr. Shyamal Chakraborty did his graduation and post-graduation from Calcutta University. He is attached to many NGO-s like Sevac,Asha Bhavan,Paripurnata and also appointed as part-time Psychiatrist in Correctional Home in Calcutta. He is a life fellow of Indian Psychiatric Society,Founder fellow of Indian Association of Private Psychiatry, Member of Indian Medical Association, Member of American Association of Geriatric Psychiatry. He is doing practice in Neuropsychiatry since 1990 and attached to Apollo Clinic,Kolkata.He attended many conferences under APA,WPA,EPA. He presented poster in ADHD conference in Italy. He chaired many conferences under Indian Psychiatric Society.He is a National Scholar and his abstracts are published in many journals in India as well as abroad.
E-mail: schakrabortydr@gmail.com